The Klein bottle was discovered in 1882 by Felix Klein and since then has joined the gallery of popular mathematical shapes.
The Klein bottle is a one-sided closed surface named after Klein. We note however this is not a continuous surface in 3-space as the surface cannot go through itself without a discontinuity.
#install.packages('animation', repos = 'http://rforge.net', type = 'source')#install.packages("plot3D")library(plot3D)library(animation)saveGIF({par(mai=c(0.1,0.1,0.1,0.1))r=3for(iin1:100){X<-seq(0,2*pi,length.out=200)#Y <- seq(-15, 6, length.out = 100)Y<-seq(0,2*pi,length.out=200)M<-mesh(X,Y)u<-M$xv<-M$y# x, y and z grids# x <- (1.16 ^ v) * cos(v) * (1 + cos(u))# y <- (-1.16 ^ v) * sin(v) * (1 + cos(u))# z <- (-2 * 1.16 ^ v) * (1 + sin(u))###### Klein bottle ##########x<-(r+cos(u/2)*sin(v)-sin(u/2)*sin(2*v))*cos(u)y<-(r+cos(u/2)*sin(v)-sin(u/2)*sin(2*v))*sin(u)z<-sin(u/2)*sin(v)+cos(u/2)*sin(2*v)################################### full colored imagesurf3D(x,y,z,colvar=z,col=ramp.col(col=c("red","red","orange"),n=100),colkey=FALSE,shade=0.5,expand=1.2,box=FALSE,phi=35,theta=i,lighting=TRUE,ltheta=560,lphi=-i)}},interval=0.1,ani.width=550,ani.height=350)
## [1] TRUE
Here is the result from the code above:
References
[Klein Bottle] (https://www.math.hmc.edu/funfacts/ffiles/30002.7.shtml)
[http://genedan.com/no-39-exploring-sage-as-an-alternative-to-mathematica/] (http://genedan.com/no-39-exploring-sage-as-an-alternative-to-mathematica/)
[Imaging maths - Inside the Klein bottle] (https://plus.maths.org/content/imaging-maths-inside-klein-bottle)
[Fun with surf3D function] (http://alstatr.blogspot.pt/2014/02/r-fun-with-surf3d-function.html)
The Package WDI (world development indicators) is used to fetch data from WDI.
We can search the data as follow:
# Load required librarieslibrary('WDI')library(ggplot2)# SearchWDIsearch(string='GDP per capita')
## indicator
## [1,] "GDPPCKD"
## [2,] "GDPPCKN"
## [3,] "NV.AGR.PCAP.KD.ZG"
## [4,] "NY.GDP.PCAP.CD"
## [5,] "NY.GDP.PCAP.KD"
## [6,] "NY.GDP.PCAP.KD.ZG"
## [7,] "NY.GDP.PCAP.KN"
## [8,] "NY.GDP.PCAP.PP.CD"
## [9,] "NY.GDP.PCAP.PP.KD"
## [10,] "NY.GDP.PCAP.PP.KD.ZG"
## [11,] "SE.XPD.PRIM.PC.ZS"
## [12,] "SE.XPD.SECO.PC.ZS"
## [13,] "SE.XPD.TERT.PC.ZS"
## name
## [1,] "GDP per Capita, constant US$, millions"
## [2,] "Real GDP per Capita (real local currency units, various base years)"
## [3,] "Real agricultural GDP per capita growth rate (%)"
## [4,] "GDP per capita (current US$)"
## [5,] "GDP per capita (constant 2000 US$)"
## [6,] "GDP per capita growth (annual %)"
## [7,] "GDP per capita (constant LCU)"
## [8,] "GDP per capita, PPP (current international $)"
## [9,] "GDP per capita, PPP (constant 2005 international $)"
## [10,] "GDP per capita, PPP annual growth (%)"
## [11,] "Expenditure per student, primary (% of GDP per capita)"
## [12,] "Expenditure per student, secondary (% of GDP per capita)"
## [13,] "Expenditure per student, tertiary (% of GDP per capita)"
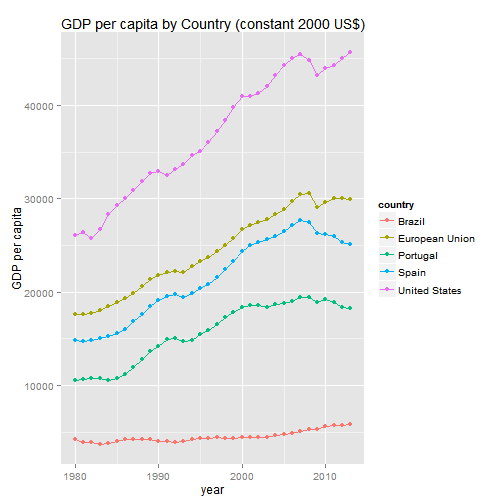
Visualizing GDP per capita
Below we import the data on GDP per capita from years 1980 to 2013 from some countries and we show a simple plot of it: GDP per capita (constant 2000 US$).
dat<-WDI(indicator=c("NY.GDP.PCAP.KD"),country=c("PT","ES","US","EU","BR"),start=1980,end=2013)#ggplot(dat,aes(year,NY.GDP.PCAP.KD,color=country))+geom_line()+geom_point()+labs(x="year",y="GDP per capita")+ggtitle("GDP per capita by Country (constant 2000 US$)")
References
[Fetching Public Data With R] (http://rstudio-pubs-static.s3.amazonaws.com/24858_1f006c3965614b0099c963913100e9f0.html)
Third using the package ggmap that allows visualizations of spatial data on maps retrieved from Google Maps, OpenStreetMap, etc., and
Fourth using the package RgoogleMaps allows you to plot data points on any kind of map you can imagine (terrain, satellite, hybrid).
1. Data from GADM database
Getting the spatial country data
library(geosphere)# use: gcIntermediatelibrary(RgoogleMaps);library(ggmap);library(rworldmap)library(sp);library(maptools);require(RColorBrewer)# PRT_adm2.RData download from http://www.gadm.org/# load("data/PRT_adm2.RData") # Creates and stores in memory an object called ´gadm´# or:# con <- url("http://biogeo.ucdavis.edu/data/gadm2/R/PRT_adm1.RData")# print(load(con))# close(con)# or:# library(raster)# port1 <- getData('GADM', country='PRT', level=1)load("data/PRT_adm1.RData")port1<-get("gadm")
Plot the map
We can use the variable NAME_1 to plot the map:
# Convert the encoding to UTF-8 in order to avoid the problems with 'accents'.# port1$NAME_1 <- as.factor(iconv(as.character(port1$NAME_1), , "UTF-8"))port1$NAME_1<-as.factor(as.character(port1$NAME_1))spplot(port1,"NAME_1",col.regions=colorRampPalette(brewer.pal(12,"Set3"))(18),col="white",#cex=0.4,xlim=range(-10,-6),ylim=range(36.9,42.2),asp=1.0#scales=list(draw=TRUE))# Plot the 'NAME_1' form the 'port1' object.
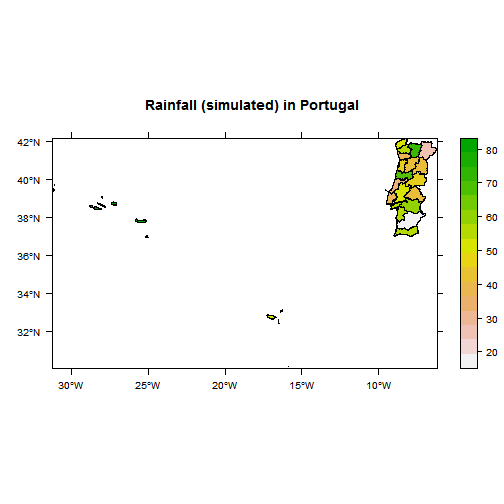
And next we created another variable called rainfall in the data.frame, we store random values in that variable:
set.seed(333)port1$rainfall<-rnorm(length(port1$NAME_1),mean=50,sd=15)#random rainfall value allocationspplot(port1,"rainfall",col.regions=rev(terrain.colors(port1$rainfall)),scales=list(draw=TRUE),main="Rainfall (simulated) in Portugal")
2. RWorldMap
Rworldmap is a package for visualising global data, referenced by country. It provides maps as spatial polygons.
newmap<-getMap(resolution="low")plot(newmap)
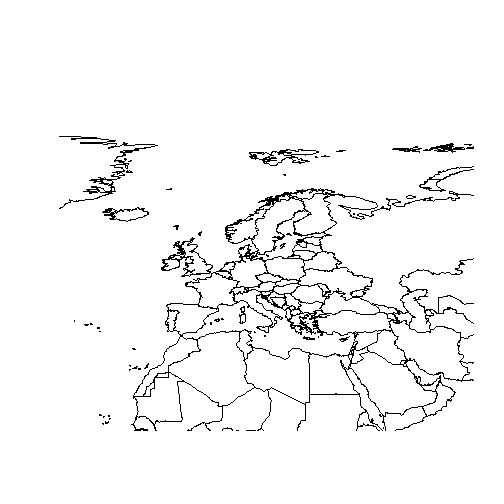
By Changing the xlim and ylim arguments of the plot function we can limit the display to just Europe.
The geocode function from the ggmap package finds the coordinates of a location using Google Maps. Thus, finding the coordinates of the Extreme points of Europe can be done by:
europe.limits<-geocode(c("CapeFligely,RudolfIsland,Franz Josef Land,Russia","Gavdos,Greece","Faja Grande,Azores","SevernyIsland,Novaya Zemlya,Russia"))europe.limits
ggmap(get_googlemap(center=c(geoCodes$lon,geoCodes$lat),#Long/lat of centrezoom=14,maptype='satellite',#also hybrid/terrain/roadmapscale=2),#resolution scaling, 1 (low) or 2 (high)size=c(600,600),#size of the image to grabextent='device',#can also be "normal" etcdarken=0)#you can dim the map when plotting on top
#ggsave ("images/map1.png", dpi = 200) #this saves the output to a file
Plotting on a Map
You can plot any [x,y, +/- z] information you’d like on top of a ggmap, so long as x and y correspond to longitudes and latitudes within the bounds of the map you have fetched. To plot on top of the map you must first make your map a variable and add a geom layer to it.
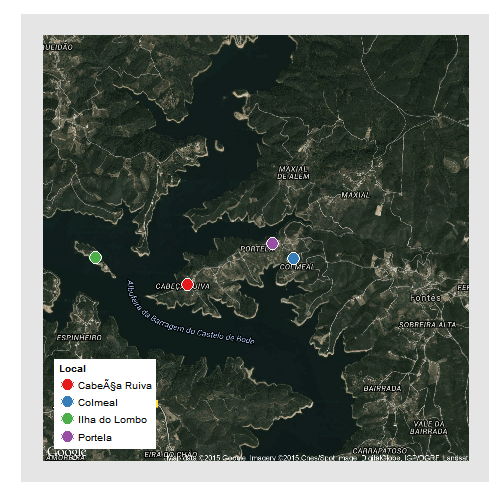
#Generate some data# lat lon# Colmeal 39.609025, -8.245660# Portela 39.610447, -8.248321# Cabeça_Ruiva 39.606380, -8.259393# Ilha_do_Lombo 39.609124, -8.271237long=c(-8.245660,-8.248321,-8.259393,-8.271237)lat=c(39.609025,39.610447,39.606380,39.609124)who=c("Colmeal","Portela","Cabeça Ruiva","Ilha do Lombo")data=data.frame(long,lat,who)map=ggmap(get_googlemap(center=c(geoCodes$lon,geoCodes$lat),zoom=14,maptype='hybrid',scale=2),size=c(600,600),extent='normal',darken=0)map+geom_point(data=data,aes(x=long,y=lat,fill=factor(who)),pch=21,colour="white",size=6)+scale_fill_brewer(palette="Set1",name="Local")+#for more info on these type ?theme() theme(legend.position=c(0.05,0.05),# put the legend INSIDE the plot arealegend.justification=c(0,0),legend.background=element_rect(colour=F,fill="white"),legend.key=element_rect(fill=F,colour=F),panel.grid.major=element_blank(),# remove major gridpanel.grid.minor=element_blank(),# remove minor gridaxis.text=element_blank(),axis.title=element_blank(),axis.ticks=element_blank())
#ggsave (""images/map2.png"", dpi = 200)
4. RgoogleMaps
‘RgoogleMaps’ allows you to plot data points on any kind of map you can imagine (terrain, satellite, hybrid).
lat<-c(37,42)#define our map's ylimlon<-c(-9,-6)#define our map's xlimlat<-c(37,42)#define our map's ylimlon<-c(-12,-6)#define our map's xlimcenter=c(mean(lat),mean(lon))#tell what point to center onzoom<-7#zoom: 1 = furthest out (entire globe), larger numbers = closer in# get maps from Googleterrmap<-GetMap(center=center,zoom=zoom,maptype="terrain",destfile="terrain.png")# visual options: # maptype = c("roadmap", "mobile", "satellite", "terrain", "hybrid", "mapmaker-roadmap", "mapmaker-hybrid")PlotOnStaticMap(terrmap)
In the lending industry, investors provide loans to borrowers in exchange for the promise of repayment with interest. If the borrower repays the loan, then the lender profits from the interest. However, if the borrower is unable to repay the loan, then the lender loses money. Therefore, lenders face the problem of predicting the risk of a borrower being unable to repay a loan.
1. Preparing the Dataset
Load the dataset loans.csv into a data frame called loans, and explore it using the str() and summary() functions.
What proportion of the loans in the dataset were not paid in full? Please input a number between 0 and 1.
Explanation </br>
From table(loans$not.fully.paid), we see that 1533 loans were not paid, and 8045 were fully paid.
Therefore, the proportion of loans not paid is 1533/(1533+8045)=0.1601.
Using a revised version of the dataset that has the missing values filled in with multiple imputation.
1.
Now that we have prepared the dataset, we need to split it into a training and testing set. To ensure everybody obtains the same split, set the random seed to 144 (even though you already did so earlier in the problem) and use the sample.split function to select the 70% of observations for the training set (the dependent variable for sample.split is not.fully.paid). Name the data frames train and test.
Now, use logistic regression trained on the training set to predict the dependent variable not.fully.paid using all the independent variables.
Which independent variables are significant in our model? (Significant variables have at least one star, or a Pr(>
Variables that are significant have at least one star in the coefficients table of the summary(model0) output. Note that some have a positive coefficient (meaning that higher values of the variable lead to an increased risk of defaulting) and some have a negative coefficient (meaning that higher values of the variable lead to a decreased risk of defaulting).
2.
Consider two loan applications, which are identical other than the fact that the borrower in Application A has FICO credit score 700 while the borrower in Application B has FICO credit score 710.
Let Logit(A) be the log odds of loan A not being paid back in full, according to our logistic regression model, and define Logit(B) similarly for loan B.
Now, let O(A) be the odds of loan A not being paid back in full, according to our logistic regression model, and define O(B) similarly for loan B. What is the value of O(A)/O(B)? (HINT: Use the mathematical rule that exp(A + B + C) = exp(A)exp(B)exp(C). Also, remember that exp() is the exponential function in R.) </br>
ans2<-exp(logA)/exp(logB)ans2
## [1] 1.098626
What is the value of O(A)/O(B)?
ANS: 1.0986257
3. Prediction Models
1.
Predict the probability of the test set loans not being paid back in full (remember type=”response” for the predict function). Store these predicted probabilities in a variable named predicted.risk and add it to your test set (we will use this variable in later parts of the problem). Compute the confusion matrix using a threshold of 0.5.
What is the accuracy of the logistic regression model? Input the accuracy as a number between 0 and 1.
What is the accuracy of the logistic regression model?
ANS: 0.8364079
What is the accuracy of the baseline model?
ANS: 0.8398886
Explanation </br>
The confusion matrix can be computed with the following commands:
test$predicted.risk = predict(mod, newdata=test, type=”response”)
table(test$not.fully.paid, test$predicted.risk > 0.5) </br>
2403 predictions are correct (accuracy 2403/2873=0.8364), while 2413 predictions would be correct in the baseline model of guessing every loan would be paid back in full (accuracy 2413/2873=0.8399).
2.
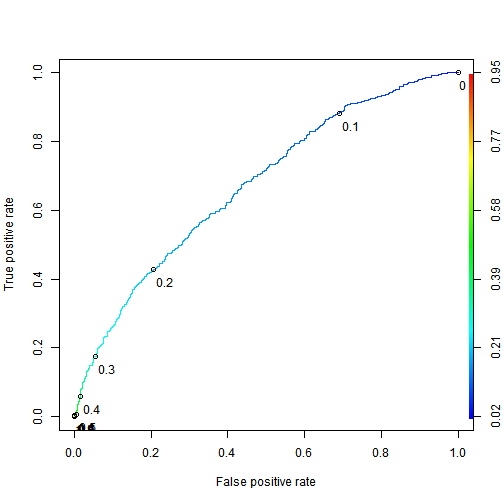
Use the ROCR package to compute the test set AUC.
Explanation </br>
The test set AUC can be computed with the following commands:
library(ROCR)
pred = prediction(test$predicted.risk, test$not.fully.paid)
as.numeric(performance(pred, “auc”)@y.values)
The model has poor accuracy at the threshold 0.5. But despite the poor accuracy, we will see later how an investor can still leverage this logistic regression model to make profitable investments.
4. A “Smart Baseline”
1.
In the previous problem, we built a logistic regression model that has an AUC significantly higher than the AUC of 0.5 that would be obtained by randomly ordering observations.
However, LendingClub.com assigns the interest rate to a loan based on their estimate of that loan’s risk. This variable, int.rate, is an independent variable in our dataset. In this part, we will investigate using the loan’s interest rate as a “smart baseline” to order the loans according to risk.
Using the training set, build a bivariate logistic regression model (aka a logistic regression model with a single independent variable) that predicts the dependent variable not.fully.paid using only the variable int.rate.
The variable int.rate is highly significant in the bivariate model, but it is not significant at the 0.05 level in the model trained with all the independent variables. What is the most likely explanation for this difference?
##
## Call:
## glm(formula = not.fully.paid ~ int.rate, family = "binomial",
## data = train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.0547 -0.6271 -0.5442 -0.4361 2.2914
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.6726 0.1688 -21.76 <2e-16 ***
## int.rate 15.9214 1.2702 12.54 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 5896.6 on 6704 degrees of freedom
## Residual deviance: 5734.8 on 6703 degrees of freedom
## AIC: 5738.8
##
## Number of Fisher Scoring iterations: 4
ANS: int.rate is correlated with other risk-related variables, and therefore does not incrementally improve the model when those other variables are included.
Explanation </br>
To train the bivariate model, run the following command:
bivariate = glm(not.fully.paid~int.rate, data=train, family=”binomial”)
summary(bivariate)
Decreased significance between a bivariate and multivariate model is typically due to correlation. From cor(train$int.rate, train$fico), we can see that the interest rate is moderately well correlated with a borrower’s credit score.
Training/testing set split rarely has a large effect on the significance of variables (this can be verified in this case by trying out a few other training/testing splits), and the models were trained on the same observations.
2.
Make test set predictions for the bivariate model. What is the highest predicted probability of a loan not being paid in full on the testing set?
According to the summary function, the maximum predicted probability of the loan not being paid back is 0.4266, which means no loans would be flagged at a logistic regression cutoff of 0.5.
3.
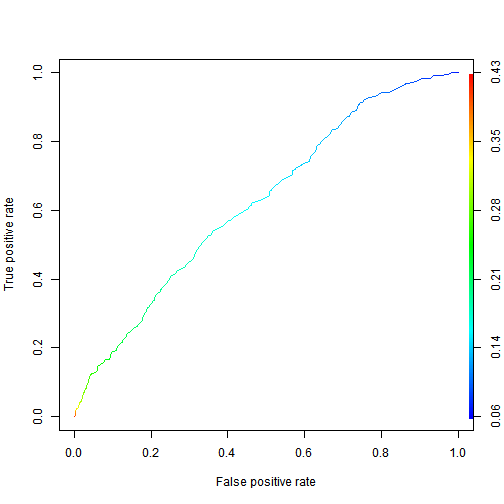
What is the test set AUC of the bivariate model?
Explanation </br>
The AUC can be computed with:
prediction.bivariate = prediction(pred.bivariate, test$not.fully.paid)
as.numeric(performance(prediction.bivariate, “auc”)@y.values)
5. Computing the Profitability of an Investment
While thus far we have predicted if a loan will be paid back or not, an investor needs to identify loans that are expected to be profitable. If the loan is paid back in full, then the investor makes interest on the loan. However, if the loan is not paid back, the investor loses the money invested. Therefore, the investor should seek loans that best balance this risk and reward.
To compute interest revenue, consider a $c investment in a loan that has an annual interest rate r over a period of t years. Using continuous compounding of interest, this investment pays back c * exp(rt) dollars by the end of the t years, where exp(rt) is e raised to the r*t power. </br>
How much does a $10 investment with an annual interest rate of 6% pay back after 3 years, using continuous compounding of interest? Hint: remember to convert the percentage to a proportion before doing the math. Enter the number of dollars, without the $ sign. </br>
10*exp(0.06*3)
## [1] 11.97217
Explanation </br>
In this problem, we have c=10, r=0.06, and t=3. Using the formula above,
the final value is 10exp(0.063) = 11.97.
6. A Simple Investment Strategy
In the previous subproblem, we concluded that an investor who invested c dollars in a loan with interest rate r for t years makes c * (exp(rt) - 1) dollars of profit if the loan is paid back in full and -c dollars of profit if the loan is not paid back in full (pessimistically).
In order to evaluate the quality of an investment strategy, we need to compute this profit for each loan in the test set. For this variable, we will assume a $1 investment (aka c=1). To create the variable, we first assign to the profit for a fully paid loan, exp(rt)-1, to every observation, and we then replace this value with -1 in the cases where the loan was not paid in full. All the loans in our dataset are 3-year loans, meaning t=3 in our calculations. Enter the following commands in your R console to create this new variable:
What is the maximum profit of a $10 investment in any loan in the testing set (do not include the $ sign in your answer)? </br>
ANS 8.8947687
Explanation </br>
From summary(test$profit), we see the maximum profit for a $1 investment in any loan is $0.8895. Therefore, the maximum profit of a $10 investment is 10 times as large, or $8.895.
summary(test$profit)
6. An Investment Strategy Based on Risk
1.
A simple investment strategy of equally investing in all the loans would yield profit $20.94 for a $100 investment. But this simple investment strategy does not leverage the prediction model we built earlier in this problem. As stated earlier, investors seek loans that balance reward with risk, in that they simultaneously have high interest rates and a low risk of not being paid back.
To meet this objective, we will analyze an investment strategy in which the investor only purchases loans with a high interest rate (a rate of at least 15%), but amongst these loans selects the ones with the lowest predicted risk of not being paid back in full. We will model an investor who invests $1 in each of the most promising 100 loans.
First, use the subset() function to build a data frame called highInterest consisting of the test set loans with an interest rate of at least 15%. </br>
What is the average profit of a $1 investment in one of these high-interest loans (do not include the $ sign in your answer)?
What proportion of the high-interest loans were not paid back in full?
ANS: 0.2517162
Explanation </br>
The following two commands build the data frame highInterest and summarize the profit variable.
highInterest = subset(test, int.rate >= 0.15)
summary(highInterest$profit)
We read that the mean profit is $0.2251.
To obtain the breakdown of whether the loans were paid back in full, we can use
table(highInterest$not.fully.paid)
110 of the 437 loans were not paid back in full, for a proportion of 0.2517.
2.
Next, we will determine the 100th smallest predicted probability of not paying in full by sorting the predicted risks in increasing order and selecting the 100th element of this sorted list. Find the highest predicted risk that we will include by typing the following command into your R console:
Use the subset() function to build a data frame called selectedLoans consisting of the high-interest loans with predicted risk not exceeding the cutoff we just computed. Check to make sure you have selected 100 loans for investment.
What is the profit of the investor, who invested $1 in each of these 100 loans (do not include the $ sign in your answer)?
This is an R Markdown document. Markdown is a simple formatting syntax for authoring HTML, PDF, and MS Word documents. For more details on using R Markdown see http://rmarkdown.rstudio.com.
When you click the Knit button a document will be generated that includes both content as well as the output of any embedded R code chunks within the document. You can embed an R code chunk like this:
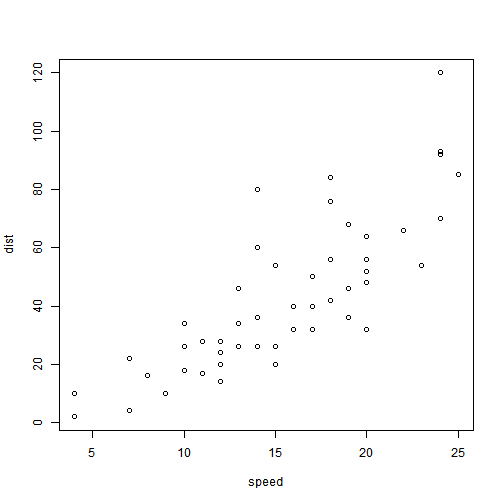
summary(cars)
## speed dist
## Min. : 4.0 Min. : 2.00
## 1st Qu.:12.0 1st Qu.: 26.00
## Median :15.0 Median : 36.00
## Mean :15.4 Mean : 42.98
## 3rd Qu.:19.0 3rd Qu.: 56.00
## Max. :25.0 Max. :120.00
You can also embed plots, for example:
Note that the echo = FALSE parameter was added to the code chunk to prevent printing of the R code that generated the plot.
Jekyll is a static site generator, an open-source tool for creating simple yet powerful websites of all shapes and sizes. From the project’s readme:
Jekyll is a simple, blog aware, static site generator. It takes a template directory […] and spits out a complete, static website suitable for serving with Apache or your favorite web server. This is also the engine behind GitHub Pages, which you can use to host your project’s page or blog right here from GitHub.
It’s an immensely useful tool and one we encourage you to use here with Hyde.